Introduction
Oracle Database 21c and 23c are the latest versions of the Oracle Database available in the market. Both of these versions offer an enhanced set of features and come with a flexible licensing model. The key highlights of this version include improved performance, better scalability, higher cloud compatibility, and enhanced security features.
As a project manager or solution architect, staying up-to-date with the latest database technology is important to ensure your organisation runs efficiently and effectively. Oracle has recently released two new database versions, Oracle Database 21c and 23c, which offer several new features and updates. In this article, we’ll discuss the licensing types available in Oracle Database 21c and how long it is supported, highlight the new features, and compare the installation cost in Oracle Cloud OCI with AWS EC2 instances.
Types of Licensing in Oracle Database 21c
Oracle Database 21c offers different licensing options depending on your organization’s needs. The first is Standard Edition 2, which is designed for small to medium-sized businesses that require basic functionality. The Enterprise Edition offers more advanced features, such as high availability and advanced security. The Enterprise Edition can also be licensed on a per-user basis or per-core basis, depending on your organization’s needs.
| Oracle Database Offering |
Offering Type |
Abbreviated Name Used in this Guide |
Description |
| Oracle Database Standard Edition 2 |
On-Premises |
SE2
|
Oracle Database Standard Edition 2 includes features necessary to develop workgroup, department-level, and Web applications.
|
| Oracle Database Enterprise Edition |
On-Premises |
EE
|
Oracle Database Enterprise Edition provides performance, availability, scalability, and security for developing applications such as high-volume online transaction processing (OLTP) applications, query-intensive data warehouses, and demanding Internet applications.
Oracle Database Enterprise Edition can be enhanced with the purchase of Oracle Database options and Oracle management packs.
|
| Oracle Database Enterprise Edition on Engineered Systems |
On-Premises |
EE-ES |
Oracle Database Enterprise Edition software installed on an on-premises engineered system (Oracle Exadata Database Machine or Oracle Database Appliance).
Includes all of the components of Oracle Database. You can further enhance this offering with the purchase of Oracle Database options and Oracle management packs.
The licensing policies for EE-ES vary depending on whether it is installed on Oracle Exadata Database Machine or Oracle Database Appliance. Be sure to make note of these differences, which are documented in the subsequent sections of this guide.
|
Per-User Licensing
Per-user licensing allows an organization to license the Oracle Database based on the number of users who will be accessing the database. Each user requires a license, regardless of how many physical or virtual cores are used by the database. This option can be cost-effective for organizations with a relatively small number of users accessing the database.
Per-Core Licensing:
Allows an organization to license the Oracle Database based on the number of physical or virtual cores used by the database. The number of licenses required is based on the number of cores allocated to the database, regardless of the number of users accessing the database. This option can be cost-effective for organizations with a larger number of users accessing the database or for databases that require a high number of cores to perform efficiently. It’s important to note that there are different types of per-core licensing models available, including named-user plus and processor-based licensing. These licensing models can affect the cost of licensing and should be carefully considered when choosing a licensing option.
It’s important to note that Oracle offers a new type of license for Oracle Database 21c called the Universal License. This license allows customers to use any feature in the Enterprise Edition for a flat fee. This is a departure from the previous model, where customers would have to purchase individual licenses for each feature they wanted to use.
More about License in Oracle
Oracle Database 21c Support
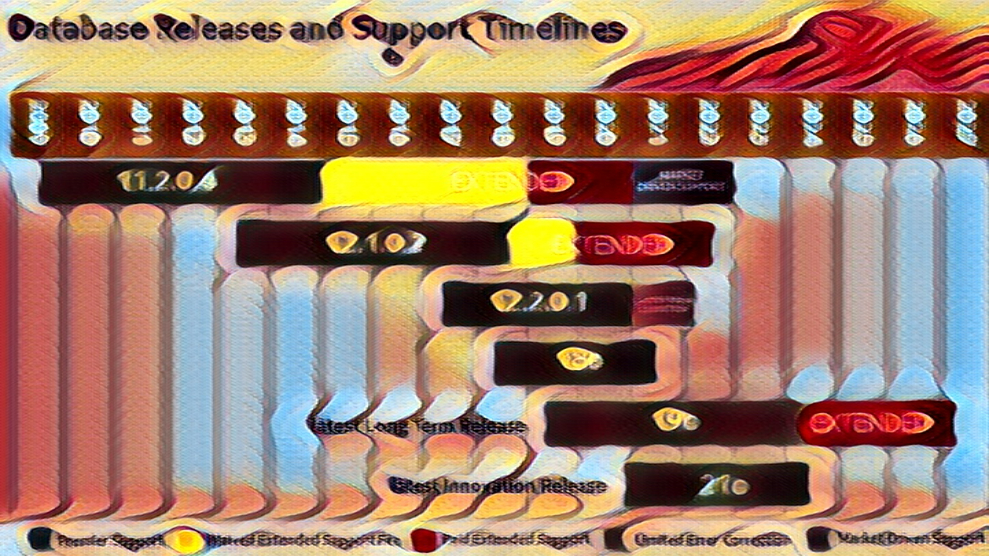
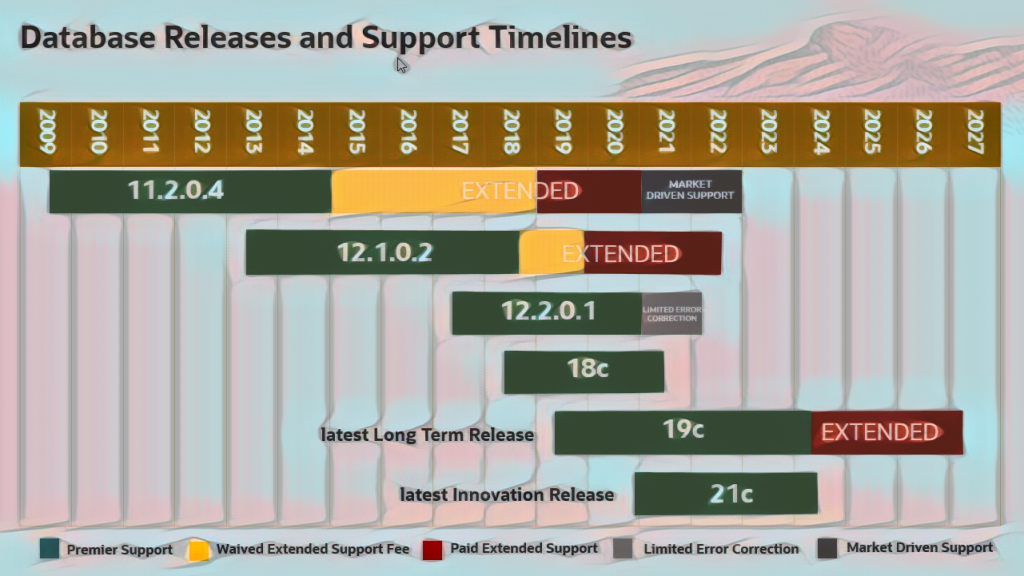
Oracle Database 21c is currently supported until at least 2026, giving organizations ample time to upgrade from previous versions. It’s important to note that support for previous versions, such as Oracle Database 19c, will eventually end, so it’s a good idea to start planning your upgrade path sooner rather than later.
New Features in Oracle Database 21c
Oracle Database 21c offers several new features and updates that can benefit your organization. Here are a few of the most notable:
Blockchain Tables
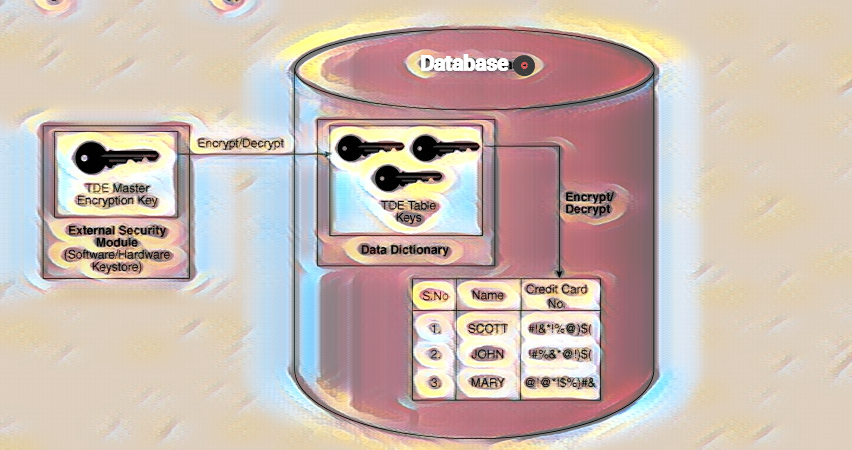
Oracle Database 21c now includes blockchain tables, allowing organizations to store and manage blockchain data. This can simplify blockchain deployment and management for organizations that use blockchain technology. Using the Blockchain Tables feature in Oracle Database 21c requires an additional license.
Native JSON Data Type:
Oracle Database 21c now includes a native JSON data type, making storing and manipulating JSON data within the database easier.
No, the use of Native JSON Datatype in Oracle Database 21c does not require an additional license. This feature is included in the standard license of Oracle Database and can be used without any additional licensing cost.
Automatic Indexing:
Oracle Database 21c includes automatic indexing, which uses machine learning algorithms to create and manage indexes automatically. This can improve query performance and reduce the need for manual index management.
Yes, the use of Automatic Indexing in Oracle Database 21c requires an additional license. Organizations that want to use this feature must purchase the Oracle Tuning Pack license, a separate add-on license.
In-Memory Database:
Oracle Database 21c includes a new in-memory database feature that allows for faster performance and processing of large datasets. This feature is useful for applications that require real-time processing of large volumes of data, such as financial trading systems, online gaming, and social media.
Yes, the use of In-Memory Database in Oracle Database 21c requires an additional license. Organizations that want to use this feature will need to purchase the Oracle Database In-Memory option, which is a separate add-on license.
Multitenant Enhancements:
Oracle Database 21c includes several enhancements to its multitenant architecture, which allow for more efficient and secure sharing of database resources among multiple tenants. This feature is useful for cloud-based applications and service providers that manage multiple databases and customers on a single server.
Hybrid Partitioned Tables:
Oracle Database 21c introduces hybrid partitioned tables, which allow for the combination of range and list partitioning in a single table. This feature is useful for applications that have complex data access patterns, such as analytics and reporting. No, the use of Hybrid Partitioned Tables does not require an additional license in Oracle Database 21c.
Cost of Installation in Oracle Cloud OCI and AWS EC2 Instance
Installing Oracle Database 21c in Oracle Cloud OCI is relatively straightforward. Oracle Cloud OCI offers several different pricing options, including pay-per-use and subscription models. The cost will depend on factors such as the size of your database, the number of users, and the level of support you require.
Comparing the cost of installation in Oracle Cloud OCI to AWS EC2 instances can be difficult, as the cost will depend on a variety of factors. However, Oracle Cloud OCI offers several advantages, such as built-in support for Oracle Database and seamless integration with other Oracle Cloud services.
Per-core licensing is a licensing model in which an organization licenses the Oracle Database based on the number of physical or virtual cores used by the database. There are different types of per-core licensing models available, including named-user plus and processor-based licensing. Here are the differences and examples of each:
Named-User Plus Licensing: Named-user plus licensing is a per-core licensing model that requires an organization to license the Oracle Database based on the number of users who will be accessing the database. Each named user requires a license, regardless of how many physical or virtual cores are used by the database. This option can be cost-effective for organizations with a relatively small number of users accessing the database.
For example, if an organization has 50 named users who will be accessing the database, and the database is running on a server with 16 cores, the organization would need to purchase 50 named-user-plus licenses. The number of cores used by the database would not affect the number of licenses required.
Processor-Based Licensing: Processor-based licensing is a per-core licensing model that requires an organization to license the Oracle Database based on the number of physical or virtual cores used by the database. The number of licenses required is based on the number of cores allocated to the database, regardless of the number of users accessing the database. This option can be cost-effective for organizations with a larger number of users accessing the database or for databases that require a high number of cores to perform efficiently.
For example, if an organization has 500 users who will be accessing the database, and the database is running on a server with 16 cores, the organization would need to purchase licenses for each core on the server. If the organization chooses processor-based licensing, it would need to purchase eight (8) licenses, one for each core on the server.
Estimating the cost of Processor-Based Licensing for an OCI Server VM.Standard 2.8 with 8 VCPUs would depend on several factors, such as the version of the Oracle Database being used, the level of support required, and any additional Oracle products or options being used.
However, as an example, let’s assume you are using Oracle Database Standard Edition 2 and require processor-based licensing. According to Oracle’s current pricing (as of March 2023), the cost of a processor license for Oracle Database Standard Edition 2 is $17,500 USD.
For a VM.Standard2.8 instance with 8 VCPUs, you would need to purchase eight (8) processor licenses. Therefore, the estimated cost of processor-based licensing for this instance would be 8 x $17,500 = $140,000 USD.
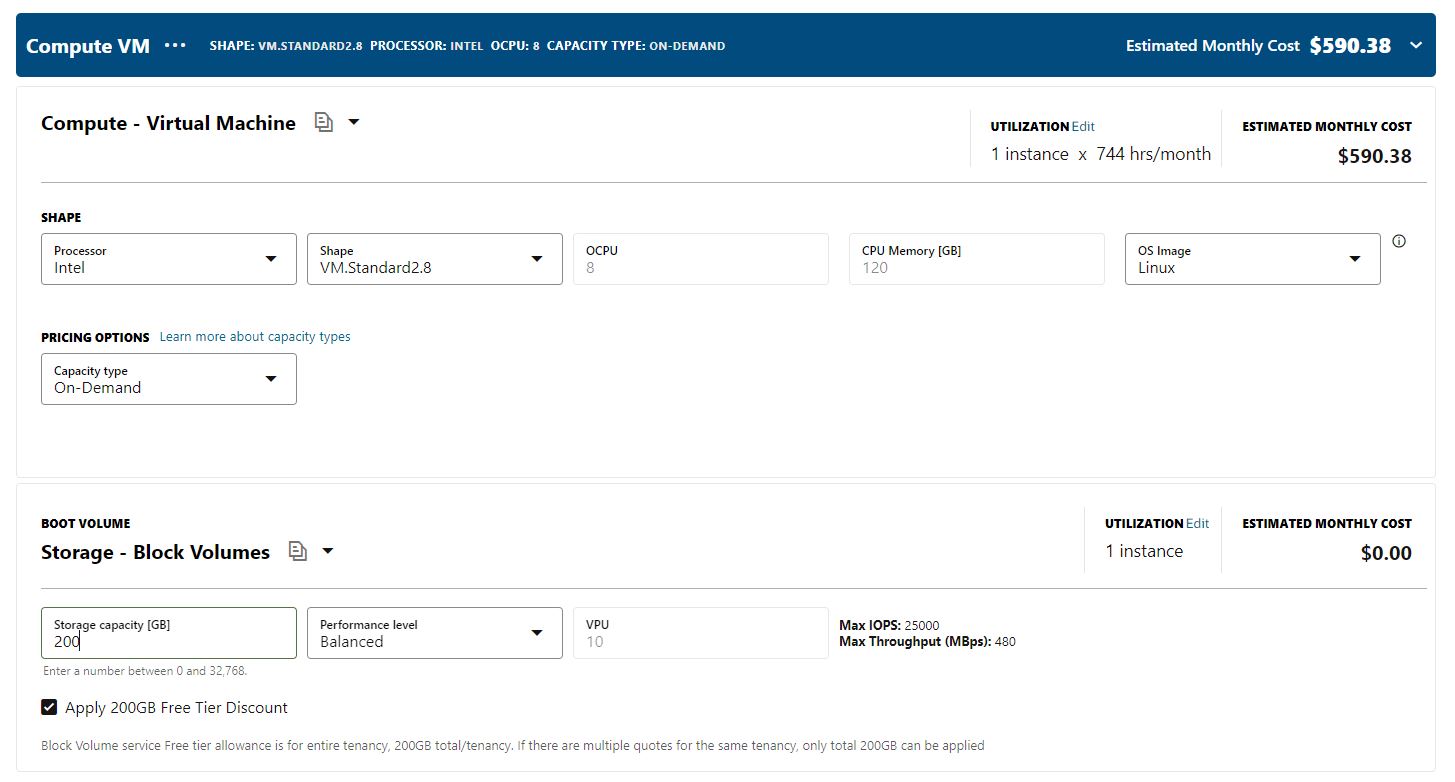
It’s important to note that this is just an estimation, and the actual cost may vary depending on the specific licensing requirements and any discounts or promotions available from Oracle. It’s recommended to consult with an Oracle representative to get a more accurate estimate based on your specific licensing needs.
Example No 2 – Cost
Let’s say we’re looking at purchasing a Dell EMC PowerEdge R740 server with two Intel Xeon Silver 4214 CPUs. According to Dell’s website, the list price for this server configuration is approximately $9,500.
It’s important to note that this price is for the server hardware only and does not include any software licenses or additional services that may be required. The total cost of a server with more than one CPU will depend on various factors, including the brand and model of the server, the number of CPUs, the amount of memory and storage, and any additional software licenses or services that may be required. Organizations should carefully consider their requirements and budget before selecting a server configuration and pricing option.
Conclusion
Oracle Database 21c and 23c offer several new features and updates that can benefit organizations of all sizes. Understanding the types of licensing available, support timelines, and new features is essential for project managers and solution architects to make informed decisions.